 |
How Banzhaf Makes a Victor: Curing a Distortion Paradox in Weighted Voting.
Jakob de Raaij,
Moon Duchin,
Ariel Procaccia, and
Jamie Tucker-Foltz.
27th ACM Conference on Economics and Computation,
July 2026.
►Abstract
[ PDF ]
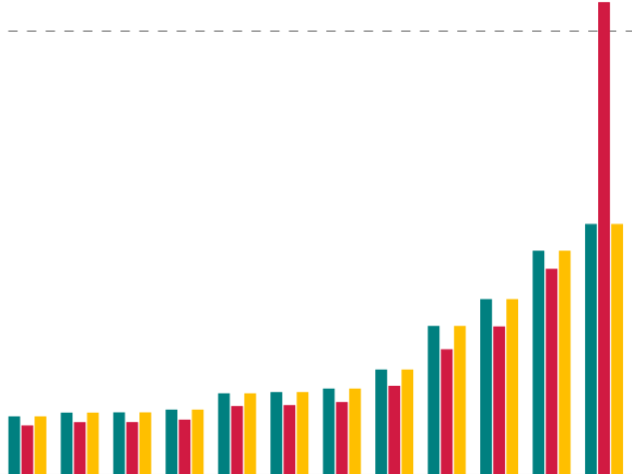
Political scientist John Banzhaf brought power indices into the legal and political spotlight in the United States by highlighting problems with naive weighting, like the possibility of "dummy players" who are never pivotal in any coalition. He argued that weighted voting should be framed as an optimization problem, with the objective that the probability of a representative casting a decisive vote is proportional to the size of their constituency. Today, there are examples (such as county government in New York State) where representatives vote with weights derived from exactly this heuristic optimization. Though there is a massive literature on power indices for weighted voting games, real-world instances
also suggest a new kind of problem not frequently discussed in research papers: with supermajority voting quotas, achieving close agreement between populations and powers can require weight vectors starkly out of proportion to both. For instance, not only contrived examples but also realistic ones can force a medium-sized player—like the Town of Victor in Ontario County, NY—to receive an "undeserving" veto, which could undermine the public legitimacy of the system. We introduce a new power index, built by having players vote yes with a probability equal to the voting quota rather than by flipping a fair coin as in ordinary Banzhaf. Among variants where players independently vote with fixed probability, this choice uniquely avoids systematic weight distortions while retaining the policy-aligned interpretation of Banzhaf power.
|
EC 2026
|
|
|
 |
The Price and Complexity of Explainable Information Design.
Yiling Chen,
Tao Lin,
Wei Tang, and
Jamie Tucker-Foltz.
27th ACM Conference on Economics and Computation,
July 2026.
►Abstract
[ PDF ]
[ arXiv ]
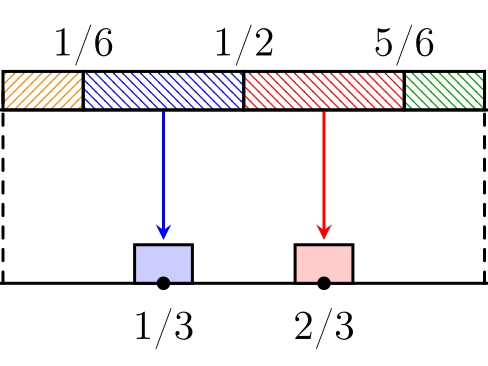
Optimal signaling schemes in information design (Bayesian persuasion) often involve randomization or disconnected partitions of state space, which might be too intricate to be audited or communicated. We propose explainable information design in the context of linear information design with a continuous state space. In the case of single-dimensional state, we restrict the information designer to use K-partitional signaling schemes defined by deterministic and monotone partitions of the state space, where a unique signal is sent for all states in each part. We prove that the price of explainability (PoE)—the ratio between the performances of the optimal explainable signaling scheme and unrestricted signaling scheme—is exactly 1/2 in the worst case, meaning that partitional signaling schemes are never worse than arbitrary signaling schemes by a factor of 2. For a uniform prior, this PoE can be improved to a tight 2/3. We then extend the analysis to multi-dimensional state spaces by studying two natural explainability notions: convex-partitional policies and axis-aligned rectangular policies. For convex-partitional policies, we prove a tight PoE of 1/(m+1), while for rectangular policies we establish a PoE guarantee under uniform prior that is independent of K but unavoidably exponential in m. On the computational side, we prove that the exact optimization of explainable policy is NP-hard in general, but provide efficient approximation methods, including an FPTAS for Lipschitz utility functions and a polynomial-time algorithm that achieves the worst-case 1/2 benchmark for the broad class of discontinuous, piecewise Lipschitz, utility functions.
|
EC 2026
|
|
|
 |
Adaptive Contracts for Cost-Effective AI Delegation.
Eden Saig*,
Tamar Garbuz,
Ariel D. Procaccia,
Inbal Talgam-Cohen, and
Jamie Tucker-Foltz.
43rd International Conference on Machine Learning,
July 2026.
►Abstract
[ PDF ]
[ arXiv ]
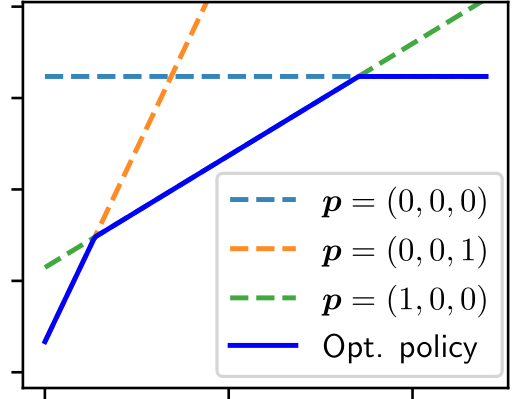
When organizations delegate text generation tasks to AI providers via pay-for-performance contracts, expected payments rise when evaluation is noisy. As evaluation methods become more elaborate, the economic benefits of decreased noise are often overshadowed by increased evaluation costs. In this work, we introduce adaptive contracts for AI delegation, which allow detailed evaluation to be performed selectively after observing an initial coarse signal in order to conserve resources. We make three sets of contributions: First, we provide efficient algorithms for computing optimal adaptive contracts under natural assumptions or when core problem dimensions are small, and prove hardness of approximation in the general unstructured case. We then formulate alternative models of randomized adaptive contracts and discuss their benefits and limitations. Finally, we empirically demonstrate the benefits of adaptivity over non-adaptive baselines using question-answering and code-generation datasets.
|
ICML 2026
|
|
|
 |
Models of Random Spanning Trees.
Eric Babson,
Moon Duchin,
Annina Iseli,
Pietro Poggi-Corradini,
Dylan Thurston, and
Jamie Tucker-Foltz.
Random Structures & Algorithms,
April 2026.
►Abstract
[ PDF ]
[ arXiv ]
There are numerous randomized algorithms to generate spanning trees in a given ambient graph; several target the uniform distribution on trees (UST), while in practice the fastest and most frequently used draw random weights on the edges and then employ a greedy algorithm to choose the minimum-weight spanning tree (MST). Though MST is a workhorse in applications, the mathematical properties of random MST are far less explored than those of UST. In this paper we develop tools for the quantitative study of random MST. We consider the standard case that the weights are drawn i.i.d. from a single
distribution on the real numbers, as well as successive generalizations that lead to product measures, where the weights are independently drawn from arbitrary distributions.
|
Rand Struct Alg
|
|
|
 |
Monotone Randomized Apportionment.
José Correa,
Paul Gölz,
Ulrike Schmidt-Kraepelin,
Jamie Tucker-Foltz, and
Victor Verdugo.
25th ACM Conference on Economics and Computation,
July 2024.
Minor revision at Operations Research.
►Abstract
[ PDF ]
[ arXiv ]
[ 20 minute EC talk ]
Apportionment is the act of distributing the seats of a legislature among political parties (or states) in proportion to their vote shares (or populations). A famous impossibility by Balinski and Young (2001) shows that no apportionment method can be proportional up to one seat (quota) while also responding monotonically to changes in the votes (population monotonicity). Grimmett (2004) proposed to overcome this impossibility by randomizing the apportionment, which can achieve quota as well as perfect proportionality and monotonicity -- at least in terms of the expected number of seats awarded to each party. Still, the correlations between the seats awarded to different parties may exhibit bizarre non-monotonicities. When parties or voters care about joint events, such as whether a coalition of parties reaches a majority, these non-monotonicities can cause paradoxes, including incentives for strategic voting.
In this paper, we propose monotonicity axioms ruling out these paradoxes, and study which of them can be satisfied jointly with Grimmett's axioms. Essentially, we require that, if a set of parties all receive more votes, the probability of those parties jointly receiving more seats should increase. Our work draws on a rich literature on unequal probability sampling in statistics (studied as dependent randomized rounding in computer science). Our main result shows that a sampling scheme due to Sampford (1967) satisfies Grimmett's axioms and a notion of higher-order correlation monotonicity.
|
EC 2024
(minor rev. OR)
|
|
|
 |
Computing Voting Rules with Elicited Incomplete Votes.
Daniel Halpern,
Safwan Hossain, and
Jamie Tucker-Foltz.
25th ACM Conference on Economics and Computation,
July 2024.
►Abstract
[ PDF ]
[ arXiv ]
[ 60 minute talk at CFCS seminar ]
Motivated by the difficulty of specifying complete ordinal preferences over a large set of m candidates, we study voting rules that are computable by querying voters about t < m candidates. Generalizing prior works that focused on specific instances of this problem, our paper fully characterizes the set of positional scoring rules that can be computed for any 1 ≤ t < m, which notably does not include plurality. We then extend this to show a similar impossibility result for single transferable vote (elimination voting). These negative results are information-theoretic and agnostic to the number of queries. Finally, for scoring rules that are computable with limited-sized queries, we give parameterized upper and lower bounds on the number of such queries a deterministic or randomized algorithm must make to determine the score-maximizing candidate. While there is no gap between our bounds for deterministic algorithms, identifying the exact query complexity for randomized algorithms is a challenging open problem, of which we solve one special case.
|
EC 2024
|
|
|
 |
Sampling Balanced Forests of Grids in Polynomial Time.
Sarah Cannon,
Wesley Pegden, and
Jamie Tucker-Foltz.
ACM Symposium on Theory of Computing,
June 2024.
►Abstract
[ PDF ]
[ arXiv ]
[ 20 minute STOC talk ]
[ 60 minute talk at Quasiworld ]
We prove that a polynomial fraction of the set of k-component forests in the m x n grid graph have equal numbers of vertices in each component, for any constant k. This resolves a conjecture of Charikar, Liu, Liu, and Vuong, and establishes the first provably polynomial-time algorithm for (exactly or approximately) sampling balanced grid graph partitions according to the spanning tree distribution, which weights each k-partition according to the product, across its k pieces, of the number of spanning trees of each piece. Our result follows from a careful analysis of the probability a uniformly random spanning tree of the grid can be cut into balanced pieces.
Beyond grids, we show that for a broad family of lattice-like graphs, we achieve balance up to any multiplicative (1 +/- epsilon) constant with constant probability, and up to an additive constant with polynomial probability. More generally, we show that, with constant probability, components derived from uniform spanning trees can approximate any given partition of a planar region specified by Jordan curves. These results imply polynomial time algorithms for sampling approximately balanced tree-weighted partitions for lattice-like graphs.
Our results have applications to understanding political districtings, where there is an underlying graph of indivisible geographic units that must be partitioned into k population-balanced connected subgraphs. In this setting, tree-weighted partitions have interesting geometric properties, and this has stimulated significant effort to develop methods to sample them.
|
STOC 2024
|
|
|
 |
School Redistricting: Wiping Unfairness Off the Map.
Ariel D. Procaccia,
Isaac Robinson, and
Jamie Tucker-Foltz.
ACM-SIAM Symposium on Discrete Algorithms,
January 2024.
►Abstract
[ PDF ]
[ 25 minute SODA talk ]
We introduce and study the problem of designing an equitable school redistricting map, which we formalize as that of assigning n students to school attendance zones in a way that is fair to various demographic groups. Drawing on methodology from fair division, we consider the demographic groups as players and seats in schools as homogeneous goods. Due to geographic constraints, not every school can be assigned to every student. This raises new obstacles, rendering some classic fairness criteria infeasible. Nevertheless, we show that it is always possible to find an almost proportional allocation among g demographic groups if we are allowed to add O(g log g) extra seats. For any fixed g, we show that such an allocation can be found in polynomial time, obtaining a runtime of O(n^2 log n) in the special (but practical) case where g ≤ 3.
|
SODA 2024
|
|
|
 |
Playing Divide-and-Choose Given Uncertain Preferences.
Jamie Tucker-Foltz and
Richard Zeckhauser.
Management Science,
January 2024.
24th ACM Conference on Economics and Computation,
July 2023.
►Abstract
[ PDF ]
[ arXiv ]
[ 20 minute EC talk ]
We study the classic divide-and-choose method for equitably allocating divisible goods between two players who are rational, self-interested Bayesian agents. The players have additive values for the goods. The prior distributions on those values are common knowledge. We consider both the cases of independent values and values that are correlated across players (as occurs when there is a common-value component).
We describe the structure of optimal divisions in the divide-and-choose game and identify several cases where it is possible to efficiently compute equilibria. An approximation algorithm is presented for the case when the distribution over the chooser's value for each good follows a normal distribution, along with a randomized approximation algorithm for the case of uniform distributions over intervals.
A mixture of analytic results and computational simulations illuminates several striking differences between optimal strategies in the cases of known versus unknown preferences. Most notably, given unknown preferences, the divider has a compelling "diversification" incentive in creating the chooser's two options. This incentive leads to multiple goods being divided at equilibrium, quite contrary to the divider's optimal strategy when preferences are known.
In many contexts, such as buy-and-sell provisions between partners, or in judging fairness, it is important to assess the relative expected utilities of the divider and chooser. Those utilities, we show, depend on the players' levels of knowledge about each other's values, the correlations between the players' values, and the number of goods being divided. Under fairly mild assumptions, we show that the chooser is strictly better off for a small number of goods, while the divider is strictly better off for a large number of goods.
|
Mgmt Sci
EC 2023
|
|
|
 |
You Can Have Your Cake and Redistrict It Too.
Gerdus Benadè,
Ariel D. Procaccia, and
Jamie Tucker-Foltz.
24th ACM Conference on Economics and Computation,
July 2023.
Operations Reseasrch,
April 2026.
►Abstract
[ PDF ]
[ arXiv ]
[ 20 minute EC talk ]
The design of algorithms for political redistricting generally takes one of two approaches: optimize an objective such as compactness or, drawing on fair division, construct a protocol whose outcomes guarantee partisan fairness. We aim to have the best of both worlds by optimizing an objective subject to a binary fairness constraint. As the fairness constraint we adopt the geometric target, which requires the number of seats won by each party to be at least the average (rounded down) of its outcomes under the worst and best partitions of the state.
To study the feasibility of this approach, we introduce a new model of redistricting that closely mirrors the classic model of cake-cutting. This model has two innovative features. First, in any part of the state there is an underlying "density" of voters with political leanings toward any given party, making it impossible to finely separate voters for different parties into different districts. This captures a realistic constraint that previously existing theoretical models of redistricting tend to ignore. Second, parties may disagree on the distribution of voters--whether by genuine disagreement or attempted strategic behavior. In the absence of a "ground truth" distribution, a redistricting algorithm must therefore aim to simultaneously be fair to each party with respect to its own reported data. Our main theoretical result is that, surprisingly, the geometric target is always feasible with respect to arbitrarily diverging data sets on how voters are distributed.
Any standard for fairness is only useful if it can be readily satisfied in practice. Our empirical results, which use real election data and maps of six US states, demonstrate that the geometric target is always feasible, and that imposing it as a fairness constraint comes at almost no cost to three well-studied optimization objectives.
|
EC 2023
OR
|
|
|
 |
Pseudorandom Finite Models.
Jan Dreier and
Jamie Tucker-Foltz.
38th Annual Symposium on Logic in Computer Science,
June 2023.
►Abstract
[ PDF ]
[ arXiv ]
We study pseudorandomness and pseudorandom generators from the perspective of logical definability. Building on results from ordinary derandomization and finite model theory, we show that it is possible to deterministically construct, in polynomial time, graphs and relational structures that are statistically indistinguishable from random structures by any sentence of first order or least fixed point logics. This raises the question of whether such constructions can be implemented via logical transductions from simpler structures with less entropy. In other words, can logical formulas be pseudorandom generators? We provide a complete classification of when this is possible for first order logic, fixed point logic, and fixed point logic with parity, and provide partial results and conjectures for first order logic with parity.
|
LICS 2023
|
|
|
 |
Topological Universality of the Art Gallery Problem.
Jack Stade and
Jamie Tucker-Foltz.
39th International Symposium on Computational Geometry,
June 2023.
►Abstract
[ PDF ]
[ arXiv ]
We prove that any compact semi-algebraic set is homeomorphic to the solution space of some art gallery problem. Previous works have established similar universality theorems, but holding only up to homotopy equivalence, rather than homeomorphism, and prior to this work, the existence of art galleries even for simple spaces such as the Möbius strip or the three-holed torus were unknown. Our construction relies on an elegant and versatile gadget to copy guard positions with minimal overhead. It is simpler than previous constructions, consisting of a single rectangular room with convex slits cut out from the edges. We show that both the orientable and non-orientable surfaces of genus n admit galleries with only O(n) vertices.
|
SoCG 2023
|
|
|
 |
Representation with Incomplete Votes.
Daniel Halpern,
Gregory Kehne,
Ariel D. Procaccia,
Jamie Tucker-Foltz, and
Manuel Wüthrich.
37th AAAI Conference on Artificial Intelligence,
February 2023.
►Abstract
[ PDF ]
[ arXiv ]
[ 60 minute talk at CFCS seminar ]
Platforms for online civic participation rely heavily on methods for condensing thousands of comments into a relevant handful based on whether participants agree or disagree with them. We argue that these methods should guarantee fair representation of the participants, as their outcomes may affect the health of the conversation and inform impactful downstream decisions. To that end, we draw on the literature on approval-based committee elections. Our setting is novel in that the approval votes are incomplete since participants will typically not vote on all comments. We prove that this complication renders non-adaptive algorithms impractical in terms of the amount of information they must gather. Therefore, we develop an adaptive algorithm that uses information more efficiently by presenting incoming participants with statements that appear promising based on votes by previous participants. We prove that this method satisfies commonly used notions of fair representation, even when participants only vote on a small fraction of comments. Finally, an empirical evaluation on real data shows that the proposed algorithm provides representative outcomes in practice.
|
AAAI 2023
|
|
|
 |
Thou Shalt Covet The Average Of Thy Neighbors' Cakes.
Jamie Tucker-Foltz.
Information Processing Letters,
November 2022.
►Abstract
[ PDF ]
[ arXiv ]
[ Official journal version ]
We prove an Ω(n^2) lower bound on the query complexity of local proportionality in the Robertson-Webb cake-cutting model. Local proportionality requires that each agent prefer their allocation to the average of their neighbors' allocations in some undirected social network. It is a weaker fairness notion than envy-freeness, which also has query complexity Ω(n^2), and generally incomparable to proportionality, which has query complexity Θ(n log n). This result separates the complexity of local proportionality from that of ordinary proportionality, confirming the intuition that finding a locally proportional allocation is a more difficult computational problem.
|
IPL
|
|
|
 |
Can Buyers Reveal for a Better Deal?
Daniel Halpern,
Gregory Kehne, and
Jamie Tucker-Foltz.
31st International Joint Conference on Artificial Intelligence,
July 2022.
►Abstract
[ PDF ]
[ arXiv ]
We study market interactions in which buyers are allowed to credibly reveal partial information about their types to the seller. Previous recent work has studied the special case of one buyer and one good, showing that such communication can simultaneously improve social welfare and ex ante buyer utility. However, with multiple buyers, we find that the buyer-optimal signalling schemes from the one-buyer case are actually harmful to buyer welfare. Moreover, we prove several impossibility results showing that, with either multiple i.i.d. buyers or multiple i.i.d. goods, maximizing buyer utility can be at odds with social efficiency, which is surprising in contrast with the one-buyer, one-good case. Finally, we investigate the computational tractability of implementing desirable equilibrium outcomes. We find that, even with one buyer and one good, optimizing buyer utility is generally NP-hard but tractable in a practical restricted setting.
|
IJCAI 2022
|
|
|
 |
Compact Redistricting Plans Have Many Spanning Trees.
Ariel D. Procaccia and
Jamie Tucker-Foltz.
ACM-SIAM Symposium on Discrete Algorithms,
January 2022.
►Abstract
[ PDF ]
[ arXiv ]
[ 20 minute SODA talk ]
[ 60 minute talk at Copenhagen-Jerusalem Combinatorics Seminar ]
In the design and analysis of political redistricting maps, it is often useful to be able to sample from the space of all partitions of the graph of census blocks into connected subgraphs of equal population. There are influential Markov chain Monte Carlo methods for doing so that are based on sampling and splitting random spanning trees. Empirical evidence suggests that the distributions such algorithms sample from place higher weight on more "compact" redistricting plans, which is a practically useful and desirable property. In this paper, we confirm these observations analytically, establishing an inverse exponential relationship between the total length of the boundaries separating districts and the probability that such a map will be sampled. This result provides theoretical underpinnings for algorithms that are already making a significant real-world impact.
|
SODA 2022
|
|
|
 |
Inapproximability of Unique Games in Fixed-Point Logic with Counting.
Jamie Tucker-Foltz.
Logical Methods in Computer Science,
2024.
36th Annual Symposium on Logic in Computer Science,
July 2021.
★ Best student paper
►Abstract
[ PDF ]
[ arXiv ]
[ LICS paper ]
[ 15 minute LICS talk ]
[ 60 minute talk at UMass CS Theory Seminar ]
We study the extent to which it is possible to approximate the optimal value of a Unique Games instance in Fixed-Point Logic with Counting (FPC). We prove two new FPC-inexpressibility results for Unique Games: the existence of a (1/2, 1/3 + delta)-inapproximability gap, and inapproximability to within any constant factor. Previous recent work has established similar FPC-inapproximability results for a small handful of other problems. Our construction builds upon some of these ideas, but contains a novel technique. While most FPC-inexpressibility results are based on variants of the CFI-construction, ours is significantly different.
|
LMCS
LICS 2021
|
|
|
 |
Multiagent Evaluation Mechanisms.
Tal Alon,
Magdalen Dobson,
Ariel D. Procaccia,
Inbal Talgam-Cohen, and
Jamie Tucker-Foltz.
6th World Congress of the Game Theory Society,
July 2021.
34th AAAI Conference on Artificial Intelligence,
February 2020.
►Abstract
[ PDF ]
[ Download AAAI paper ]
[ 20 minute GAMES talk ]
We consider settings where agents are evaluated based on observed features, and assume they seek to achieve feature values that bring about good evaluations. Our goal is to craft evaluation mechanisms that incentivize the agents to invest effort in desirable actions; a notable application is the design of course grading schemes. Previous work has studied this problem in the case of a single agent. By contrast, we investigate the general, multi-agent model, and provide a complete characterization of its computational complexity.
|
GAMES 2021
AAAI 2020
|
|
|
 |
Computational Topology and the Unique Games Conjecture.
Joshua A. Grochow and
Jamie Tucker-Foltz.
34th International Symposium on Computational Geometry,
June 2018.
►Abstract
[ PDF ]
[ Download SoCG paper ]
[ arXiv ]
Covering spaces of graphs have long been useful for studying expanders (as "graph lifts") and unique games (as the "label-extended graph"). In this paper we advocate for the thesis that there is a much deeper relationship between computational topology and the Unique Games Conjecture. Our starting point is Linial's 2005 observation that the only known problems whose inapproximability is equivalent to the Unique Games Conjecture—Unique Games and Max-2Lin—are instances of Maximum Section of a Covering Space on graphs. We then observe that the reduction between these two problems (Khot-Kindler-Mossel-O'Donnell, FOCS 2004 and SICOMP, 2007) gives a well-defined map of covering spaces. We further prove that inapproximability for Maximum Section of a Covering Space on (cell decompositions of) closed 2-manifolds is also equivalent to the Unique Games Conjecture. This gives the first new "Unique Games-complete" problem in over a decade. Our results partially settle an open question of Chen and Freedman (SODA 2010 and Disc. Comput. Geom., 2011) from computational topology, by showing that their question is almost equivalent to the Unique Games Conjecture. (The main difference is that they ask for inapproximability over Z/2Z, and we show Unique Games-completeness over Z/kZ for large k.) This equivalence comes from the fact that when the structure group G of the covering space is Abelian—or more generally for principal G-bundles—Maximum Section of a G-Covering Space is the same as the well-studied problem of 1-Homology Localization. Although our most technically demanding result is an application of Unique Games to computational topology, we hope that our observations on the topological nature of the Unique Games Conjecture will lead to applications of algebraic topology to the Unique Games Conjecture in the future.
|
SoCG 2018
|
|
|
*All publications list authors in alphabetical order by convention, except those with starred authors, which were moved to the front with the rest alphabetical.

